

Zentrales Identity Management und Access Kontrolle mit Atlassian Crowd
21.03.2017 / 0 Comments
Wie funktioniert Single Sign-On (SSO) über Atlassian JIRA & Confluence?
Zur Nutzung eines SSO für Atlassian JIRA & Confluence gibt es mehrere Möglichkeiten.
- Methode 1: JIRA als zentrales Benutzerverwaltungssystem für Confluence benutzen.
- Methode 2: Crowd als Benutzerverwaltungssystem für JIRA & Confluence nutzen.
Beide Möglichkeiten funktionieren auch für JIRA Service Desk, sowie die Data Center Versionen der Systeme.
Methode 1: JIRA als zentrales Benutzerverwaltungssystem für Confluence benutzen
Es ist möglich die Benutzerdatenbank eines JIRA-Systems für Confluence zu nutzen und so den Aufwand für die Verwaltung der Benutzer zu reduzieren.
Bei dieser Methode gibt es eine Einschränkung, die im Folgenden erklärt wird.
Wenn ein Benutzer in JIRA erstellt wird, so erhält er die Gruppenzugehörigkeit zu „jira-software-users“/ „jira-users“ und kann somit direkt und ohne weitere Konfiguration auch auf Confluence zugreifen.
Wenn aber ein Benutzer in Confluence erstellt wird, erhält er die Gruppenzugehörigkeit zu "confluence-user“ und hat damit nur die Möglichkeit sich bei Confluence anzumelden, nicht aber bei JIRA. Hierfür muss dem Nutzer zusätzlich manuell die Gruppe „jira-software-users“/ „jira-users“ hinzugefügt werden.
Zwei Möglichkeiten der Konfiguration
Zur Einrichtung der Verbindung besteht sowohl die Möglichkeit ein neues Confluence-Systeme direkt mit JIRA zu verbinden (A), als auch für bestehende Systeme die Verwendung von JIRA zu ermöglichen (B).
Methode A: Ein neues Confluence-System einrichten
Während der Einrichtung des Confluence Servers, bietet einem der Wizard die Möglichkeit, die Benutzerverwaltung von einem JIRA-System übernehmen zu lassen.
Hierbei ist es nicht nötig, dass JIRA und Confluence auf einem Server laufen, sondern es ist auch eine Verbindung zu einem anderen Server möglich.
Hierfür wird im weiteren Verlauf des Assistenten nach der URL des JIRA-Servers gefragt.

Außerdem benötigt der Assistent die Anmeldedaten eines Admin-Zugangs zum JIRA-System.

Des Weiteren ist es möglich, Anpassungen vorzunehmen, zum Beispiel, um einen Proxy-Server verwenden zu können oder aber die privilegierten Gruppen festzulegen, falls diese nicht den Standardgruppen entsprechen. ( Beispielweise heißt die Standardgruppe für Benutzer in neueren Versionen von JIRA nicht mehr „jira-users“, sondern „jira-software-users“ )

Anschließend erledigt der Assistent die restliche Einrichtung und es wird ein Administrator-Account erstellt, der dieselben Login-Daten verwendet, wie der eingetragene Admin-Account für JIRA.
Nun ist die Einrichtung abgeschlossen und Confluence nutzt dieselben Benutzerdaten wie JIRA.
Methode B: Ein laufendes Confluence-System einrichten
Um ein bestehendes Confluence-System mit JIRA zu verbinden, ist es zuerst nötig JIRA so zu konfigurieren, dass es Anfragen von Confluence bearbeiten kann.
Konfiguration von JIRA
Hierfür ruft man die Benutzerverwaltung über das Administrations-Menü oben rechts auf.
Nun erscheint auf der linken Seite der Eintrag Jira-Benutzerserver, den man auswählt.
Es werden nun alle Anwendungen angezeigt, die Zugriff auf das Benutzersystem von JIRA haben.
Durch drücken auf „Anwendung hinzufügen“, ist es nun möglich Confluence den Zugriff zu ermöglichen.
Hierfür müssen wir einen Login für die Anwendung festlegen. Dieser besteht aus einem Anwendungsnamen und einem Passwort. Diese Daten werden später in Confluence benötigt.
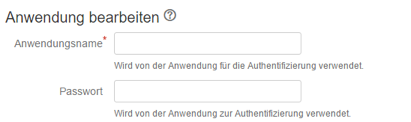
Außerdem muss die URL des Confluence-Servers eingegeben werden, damit JIRA die Anfragen der richtigen Anwendung zuordnen kann und sie entsprechend richtig bearbeitet.
Mit einem Klick auf „Speichern“ beenden wir die Konfiguration von JIRA und wechseln zu unserem Confluence-System.
Konfiguration von Confluence
Um ein bestehendes Confluence-System mit JIRA zu verbinden, benötigt man auch hierfür Admin-Rechte.
Erneut ruft man die Benutzerverwaltung innerhalb von Confluence über das Administration-Menü rechtsoben auf.
Nun scrollt man nach unten, bis in der linken Navigationsleiste der Eintrag „Benutzerverzeichnisse“ unter dem Oberpunkt „Benutzer & Sicherheit“ auftaucht und wählt diesen aus.
Jetzt erscheint die Liste der verbundenen Verzeichnisse.
Hier sollte im Normalfall nur das Confluence-interne Verzeichnis („Confluence Internal Directory“) zu sehen sein.
Nun kann man über den Button „Verzeichnis hinzufügen“ ein neues Verzeichnis hinzufügen.
Als Typen wählt man nun Atlassian-JIRA aus der Liste aus und drückt weiter.
Jetzt muss die Konfiguration erfolgen und einige Informationen eingegeben werden, damit die Zusammenarbeit der beiden Systeme funktioniert.
Als erstes kann man dem Verzeichnis einen Namen geben, damit man es später in der Liste identifizieren kann.

Außerdem wird die URL des JIRA-Servers benötigt, sowie die Daten für die Anwendungsanmeldung, die weiter oben festgelegt wurden.
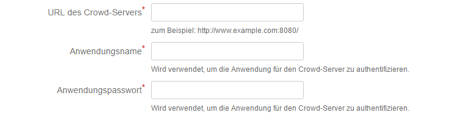
Die weiteren Textfelder sind optional und können benutzt werden, wenn die Standardeinstellungen geändert werden wollen oder ein Proxy-Server verwendet werden soll.
Des Weiteren steht nun zur Auswahl, ob Confluence Lese- und Schreibzugriff erhalten soll oder das Verzeichnis schreibgeschützt bleiben soll und nur gelesen werden kann.

Wählt man hier schreibgeschützt, so kann man in Confluence keine Benutzer erstellen und im Verzeichnis speichern oder löschen, sondern lediglich existierende Benutzer zur Authentifizierung nutzen. Änderungen am Verzeichnis sind nur über JIRA möglich.
Bei Schreib- und Lesezugriff dagegen, kann man das Verzeichnis über Confluence verändern und Nutzer hinzufügen und löschen, ohne sich hierfür in JIRA anzumelden und dort die Änderungen vorzunehmen.
Die erweiterten Einstellungen ermöglichen es verschachtelte Gruppen zu erstellen, welche aber Einfluss auf die Systemperformance haben können, da unter Umständen viele Referenzen aufgelöst werden müssen.
Außerdem kann die inkrementelle Synchronisation abgeschaltet werden, welche die Synchronisation vereinfacht, indem nur die letzten Änderungen und nicht das gesamte Verzeichnis neu geladen wird.
Das Synchronisationsinterval gibt an, in welchem Abstand das Verzeichnis automatisch auf Änderungen überprüft werden soll. Ein manuelles Starten der Synchronisation ist jederzeit möglich.
Nun werden die Einstellungen getestet und danach gespeichert.
Internes Verzeichnis zur Sicherung möglich
Nun kann man noch entscheiden, ob man ausschließlich die Benutzerdaten aus JIRA nutzen möchte oder Confluence ein lokales Verzeichnis belassen möchte. Das lokale Verzeichnis ist vor allem dann sinnvoll, wenn man nur Schreibzugriff auf das JIRA-Verzeichnis hat, da ansonsten innerhalb von Confluence keine Nutzer angelegt werden können, sondern jeder Account über JIRA erstellt werden muss. Außerdem ist es sinnvoll einen Administrator innerhalb des Confluence Verzeichnis zu belassen, mit Hilfe dessen man Probleme behandeln kann, wenn die Verbindung zu JIRA abbrechen sollte.
Soll ein eigenes Verzeichnis geführt werden, so kann man noch die Reihenfolge der Verzeichnisse festlegen. So wird immer zuerst das oberste Verzeichnis verwendet, um Anfragen aufzulösen.
Änderungen werden ebenfalls in das erste Verzeichnis geschrieben, zu welchem Confluence Schreibzugriff hat.
Um das interne Confluence-Verzeichnis zu löschen, muss man sich zuerst mit einem Administrator-Account aus dem JIRA-Verzeichnis anmelden, da ansonsten ein Löschen des Confluence-Verzeichnisses nicht möglich ist.
Nun ist die Konfiguration der Verbindung von JIRA und Confluence abgeschlossen und Confluence nutzt das JIRA-Verzeichnis für die Logins.
Methode 2: Crowd als Benutzerverwaltungssystem für JIRA & Confluence nutzen.
Als weitere Vereinfachung der Benutzerverwaltung ist es möglich JIRA & Confluence mit Crowd zu verbinden. Der Vorteil von Crowd gegenüber der Verwaltung mit JIRA ist die Möglichkeit Authentifizierungen anderer Dienste auch über Crowd durchzuführen. Neben anderen Atlassian-Anwendungen kann man auch eigene Apps und Dienste über Crowd authentifizieren lassen. Dadurch gibt es dann ein zentrales Benutzerverwaltungssystem für alle Anwendungen, welches jedem Benutzer Zugriff zu bestimmten Anwendungen gewähren kann.
Das SecSign ID Crowd Plugin kann schnell und einfach integriert werden. Ausführliche Informationen über das Plugin und die Integration können den folgenden Seiten entnommen werden.
Sie haben noch Fragen? Zögern Sie nicht, sich mit uns in Verbindung zu setzen.
Verbinden mit bereits bestehenden Verzeichnisdiensten
Außerdem ist es in Crowd möglich, bereits bestehende Verzeichnisdienste einzubinden und so bereits bestehende Accounts für andere Anwendungen und Dienste in JIRA & Confluence, sowie anderen Atlassian-Diensten zu nutzen.
Direkt unterstützte Verzeichnisdienste sind zum Beispiel Microsoft Active Directory, Apache Directory Server und Apple Open Directory.
Aber auch andere Verzeichnisdienste sind mit entsprechender Konfiguration möglich.
Bei den meisten Verzeichnisdiensten besteht sowohl die Möglichkeit diese nur lesend zu verwenden und keine Änderungen an den Verzeichnissen zu erlauben, als auch Änderungen innerhalb von Crowd oder den verwendeten Diensten, direkt in das externe Verzeichnis übernehmen zu lassen, welches wiederrum zu weniger Verwaltungsaufwand führt.
Sobald das entsprechende Verzeichnis mit Crowd verbunden ist, kann man den Nutzern in bereits definierten Gruppen Zugriff zu den verschiedenen Anwendungen geben. Alternativ kann man neue Gruppen erstellen und nur diesen Gruppen Zugriff geben.
Wie läuft der Login mit Crowd genau ab?
Für den Benutzer ändert sich nichts. Der Login sieht identisch aus und funktioniert wie sonst auch.
Einzig im Hintergrund ändern sich einige Dinge.
Je nach Einstellung, werden Benutzer und Gruppen aus externen Verzeichnissen in Crowd zwischengespeichert, um diese Informationen schneller zu erhalten, wenn beispielweise die Gruppen oder Benutzer einer Gruppe angezeigt werden soll.
Der Login selber allerdings wird bei einem externen Verzeichnisdienst immer direkt beim Verzeichnisdienst authentifiziert. Es werden also keine Passwörter aus dem Verzeichnisdienst synchronisiert, sondern diese bleiben sicher im Verzeichnis und werden dort über entsprechende Schnittstellen zur Authentifizierung genutzt.
Crowd als Zentralisierung oder Kapselung
Crowd kommt mit einer übersichtlichen grafischen Admin-Konsole, die jegliche Verwaltungsarbeiten sehr einfach ermöglicht.
Es besteht außerdem die Möglichkeit neben der Verbindung mit Crowd, zum Beispiel in JIRA, ein eigenes zusätzliches Verzeichnis zu erstellen, welches dann lokale Benutzer beinhaltet, die nur JIRA bekannt sind. So ist es möglich für bestimmte Anwendungen Nutzerkreise zu erstellen, die dann ausschließlich Zugriff zu dem Produkt haben und über das Produkt selbst verwaltet werden können, ohne Einfluss auf andere Verzeichnisse zu nehmen.
Crowd ermöglicht also sowohl die Zentralisierung von Anmeldedaten, als auch die Kapselung einzelner Gruppen und Anwendungen und ermöglicht so jedes denkbare Szenario einer wünschenswerten Benutzerverwaltung.
Eintrag teilen




Kategorien
- Allgemein (27)
- Apple (9)
- Atlassian (4)
- Biometrics (5)
- SecSign Portal (3)
- Wordpress (2)
- Zwei-Faktor Authentifizierung (22)
Kontaktieren Sie uns
Vertrieb
Würden Sie gerne mehr über unsere innovativen und hochsicheren Lösungen zum Schutz von Nutzerkonten und empfindlichen Daten erfahren?
Nutzen Sie unser Kontaktformular und ein SecSign Kundenbetreuer wird innerhalb eines Arbeitstages Kontakt mit Ihnen aufnehmen.
Kundensupport
Benötigen Sie Hilfe mit einem existierenden SecSign Account oder einer Produktinstallation? Die häufigsten Fragen haben wir in unseren FAQs zusammengefasst. Sie finden keine Lösung zu Ihrem Problem? Kontaktieren Sie den
Kundensupport
Ich Interessiere mich für